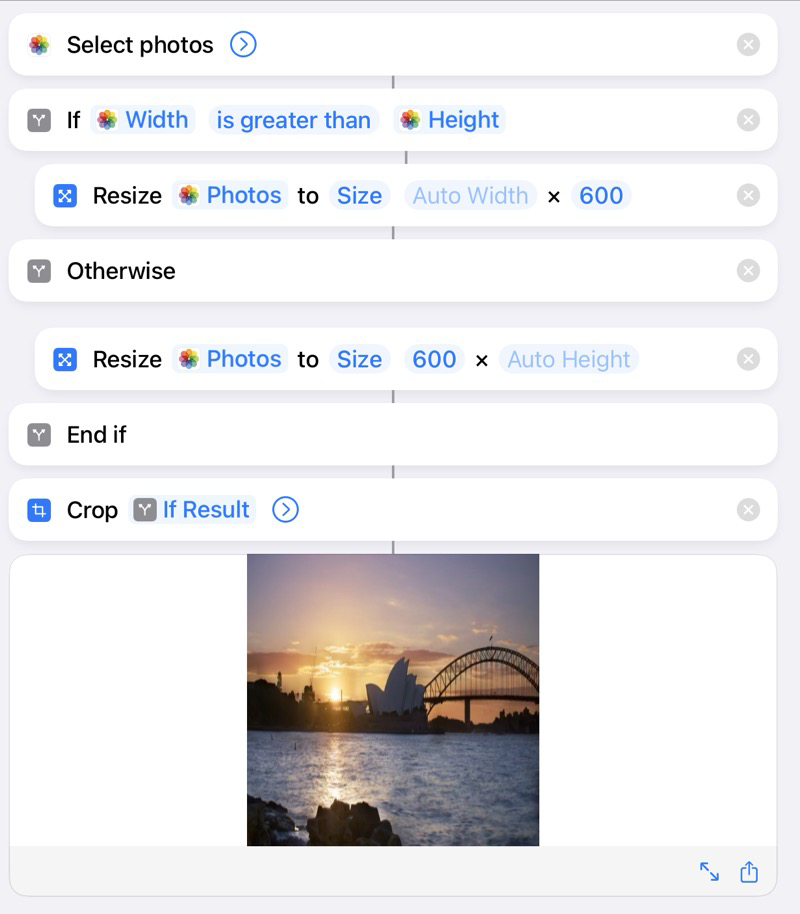
In the last six months or so I have become an enthusiastic hobbyist photographer. This started with paying more attention to how I used the camera on my phone, then quickly progressed into buying a Sony a6000 mirrorless camera. Before I knew it I had two tripods, a camera bag, an ND filter, and was starting to browse through lenses on Amazon.
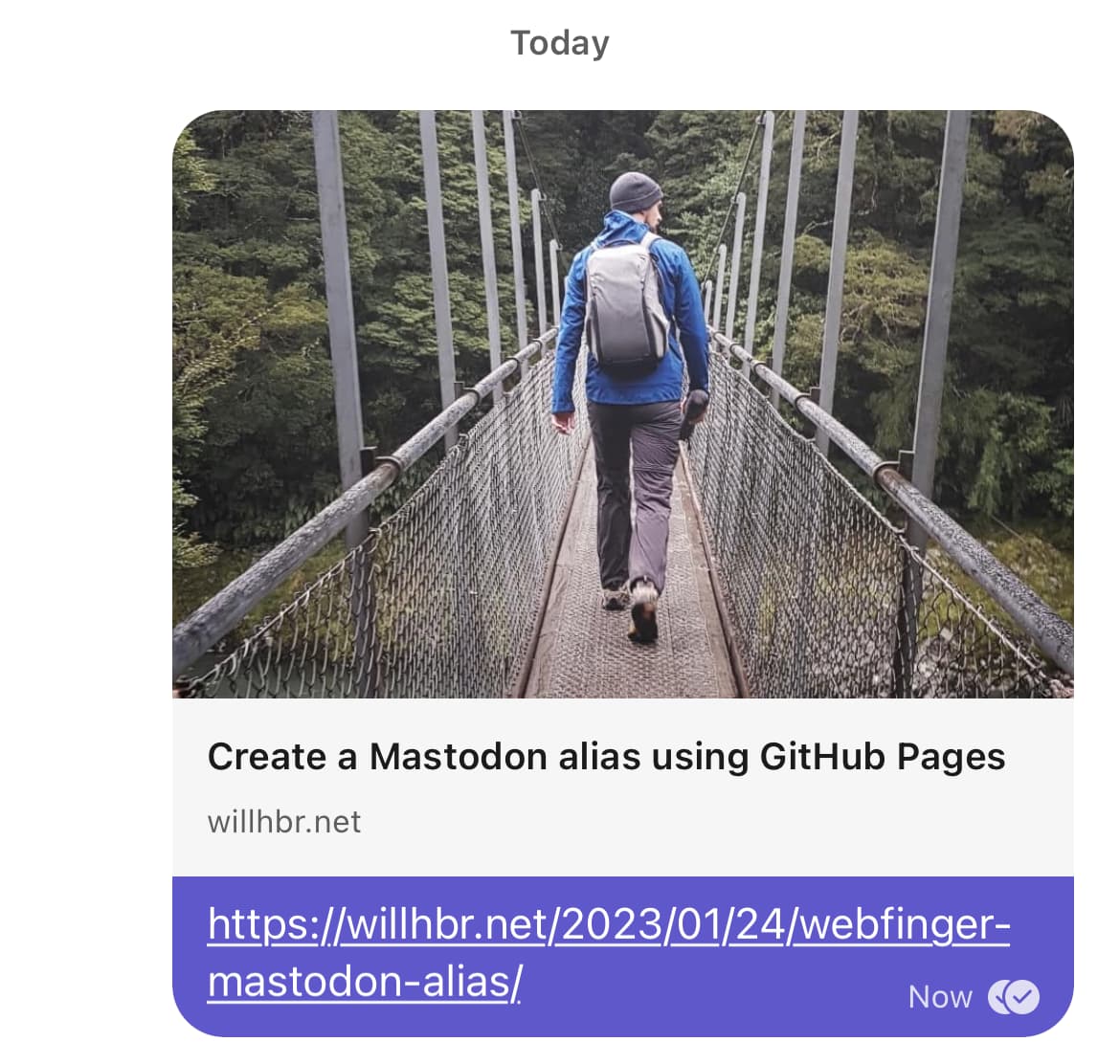
These photos usually end up on my Instagram. Here’s one from the other day:

All the photos that I take on my camera are edited on my iPad using Pixelmator Photo. It’s an amazingly powerful piece of software - especially considering that it’s less than $10.
Importing and editing photos from a camera is easy on iOS. You just need the appropriate dongle - in this case it’s just a USB C SD card reader - and tap “Import” in the Photos app. It removes duplicates and can even clear the photos off the card once the import is complete. What more could you want?
Much, much more.
The problem first started when a friend of mine suggested that I start shooting raw photos to make use of the extra dynamic range. If you’re not aware, raw photos contain very little processing from the camera and are not compressed - unlike jpegs. On the a6000 a typical jpeg is less than 10MB, whereas a raw photo is 24MB. This meant that whenever I took my camera anywhere, I could easily produce 20GB of photos instead of the more reasonable 1-2GB.
There are two big problems here:
- my iPad only has 250GB of storage
- my home internet is too slow to upload this many photos to Google Photos
My first thought was to just dump my unused photos onto an external drive (now that iOS 13 adds support for them natively) and delete them from my iPad. This works OK for video - you have a handful of files, each of which are a few gigabytes. Background processing isn’t great in iOS, but I can deal with having to keep the app open in the foreground while the copy is happening.
This is not the case with photos. You instead have hundreds and hundreds of small files, so if the copy fails you have no idea how much you have to continue with. That being said, if you were shooting jpegs, you could do something like:
- import into the Photos app
- swap the SD card out for an external drive
- select all the photos you just imported (hoping that you can just select in a date range)
- drag the photos into a folder on the external drive
- baby sit the Files app while it copies
Less than ideal, but workable. Ok, now why won’t that work for raw files?
iOS kinda only pretends that it supports raw files. If you import them into the Photos app there is no indication of the file type, but third party apps can access the raw data. What’s frustrating is that when you export the photos, only the jpeg is exported. So if you try and drag raw photos onto an external drive, you lose the raw data.
Basically, Photos on iOS is a one-way street for raw images. They’ll be imported, but can’t be exported anywhere without silent data loss.
Alright so using the Photos app is a bit of a loss. Can we just keep all the images as files instead? The short answer is “not very well”.
Importing from an SD card to the Files app can only be done as a copy - no duplicate detection, no progress indication, etc. You just have to sit there hoping that nothing is being lost, and if it fails in the middle you probably just have to start again.
Once the photos are in the Files app, you have to do the same dance again to export them to your external drive. Cross your fingers and hope that nothing gets lost.
Also remember that once the photos have been exported, the Files app will be unable to show the contents of the folder - it’ll just sit on “Loading” presumably trying to read every file and generate hundreds of thumbnails. And there’s no way to unmount the drive to ensure that the data has been correctly flushed to disk, you just have to pull the cable out and hope for the best.
Thankfully Pixelmator Photo does support opening images from the Files app, so you can import them from there without much trouble. But there is no way to quickly delete photos that weren’t in focus or get rid of the bad shots out of a burst. (This isn’t great in the Photos app either, but at least the previewing is acceptable).
So you’re left with a bunch of files on your iPad that you have to manage yourself, and a backup of photos on your external drive that you can’t look at unless you read the whole lot back. Not good.
“Why don’t you just use a Mac” - the software that I know how to use is on iOS. My iPad is faster than my Mac. The screen is better. I can use the Pencil to make fine adjustments.
“Why not use Lightroom and backup to Adobe CC” - I don’t want to have to pay an increasing recurring cost for something that is a hobby. Also I like using Pixelmator Photo (or Darkroom, or regular Pixelmator, or maybe Affinity Photo when I get around to learning how it works).
“Just get an iPad with more storage” - I’d still have the same problem, just in about a year.
This is the point in the blog post that I would like to be able to say that I have a neat and tidy solution. But I don’t. This is a constant frustration that stops me from being able to enjoy photography, because for every photo I take I know that I’m just making everything harder and harder to manage.
One solution could be to connect my external drive to my home server, and find an app that allows me to backup to that. This seems ridiculous as my iPad can write to the drive directly.
I think the only thing that can make this practical - outside of iOS getting much better at managing external drives - is to make an app that reads the full image data from Photos, and writes to a directory on an external drive. It could also keep a record of what it has exported, and allow for cleaning up any photos that didn’t get edited automatically. The workflow would look something like:
- attach SD card and import into Photos app
- attach external drive and use photo exporting app to copy new photos onto the drive
- edit/delete photos using any app that takes your fancy
- use photo export app to remove any photo that wasn’t edited or marked in some way (eg, favorited) in one go
This would patch over the poor experience of copying to external drives, making iOS-only photography more practical for people who don’t want to pay for cloud storage for hundreds of mediocre shots.
Here’s hoping that iOS will continue to improve and become more flexible for different workflows.
If you’re an iOS developer who wants to make an app with probably the most limited appeal ever, get in touch.