I’m a very heavy user of tmux, and like to share how I make the most of it. This was going to be a short list of some nice things to know and some pointers to features people might not be aware of, but then I realised it’s probably easier to just explain the stuff that I have configured, and so here we are. I grabbed the current version of my tmux.conf and added an explanation after each section.
This assumes that you use tmux in the same way that I do. Some people like to just use it as a way to get a few pre-defined splits in their terminal and they never want to change those splits. Other people just use it in case their ssh connection drops. When I’m working I basically always have a large or full-screen terminal open that’s connected via SSH to a server, and on server running tmux attached to a session for the specific project that I’m working on. If I work on a different project I’ll just detach from that session and start a new one.
So with that in mind, let’s dive in…
# GENERAL BITS AND BOBS
unbind -T root -aq
unbind -T prefix -aq
unbind -T nested -aq
unbind -T popup -aq
unbind -T copy-mode -aq
The unbind command will remove all bindings in a key table. I do this so that anything I set while tinkering will get unset and replaced with the config (reducing the chances of getting into a weird state), and because I’ve chosen to redefine every key binding myself, this removes any double-ups. This is not something that I’d recommend others do, since you’ve got to be pretty familiar with all the bindings that you use regularly and define them yourself before this is actually practical.
In tmux a key-table is just a set of key bindings. The two most important ones are prefix and root. The prefix table contains all the bindings that can be used after you enter your prefix key, and root contains all the bindings that can be done without having to first enter the prefix.
The prefix key is just tmux’s way of “namespacing” its shortcuts off so you’re not going to have a conflict with another program. tmux doesn’t add any key bindings in the root table by default.
Since I know the programs that I’m going to be using—and know the keys that I’ll use in those programs—I heavily use the root key table to add shortcuts that are faster to activate (and activate repeatedly) without having to first press the prefix.
You can totally abuse the root key-table too, for example you can make a binding so that whenever you press “a”, “b” is what gets sent to the shell:
bind-key -T root a send-keys b
bind-key -n is just a short-hand for bind-key -T root.
set -g mode-keys vi
set -g status-position bottom
set -g base-index 1
set -g renumber-windows on
set -g default-terminal 'screen-256color'
set -g history-file ~/._tmux-history
# set -g prompt-history-limit 10000
This is just some fairly basic config for the standard behaviour of tmux. I use vim keybindings for copy-mode since those are the shortcuts I am familiar with. The status bar (with the list of windows, etc) lives at the bottom. Windows are numbered starting from 1 instead of 0, since if I use a “switch to window X” shortcut, having the window indices match the order of the keys on a keyboard is nice. Although I don’t actually use the shortcuts for switching directly to a window by number, since it’s almost always faster for me to just mash “next window” a bunch of times until I’ve got the window I need.
When I first started using tmux I think I had default-terminal incorrectly set to xterm-256color—the standard for most terminal emulators—which caused some background colours to render incorrectly. It should basically always be screen-256color unless you’re doing something weird where you don’t have 256 colours, but that’s unlikely. It might be set to this by default in tmux, but I just keep this here to be sure.
set -g prefix C-z
bind C-z send-prefix
bind r {
source-file ~/.tmux.conf
display 'config reloaded'
}
As I’ve mentioned before, I use C-z as my prefix shortcut. It’s more convenient to press than the default C-b, and I don’t suspend tasks using C-z very often (which is what it usually does). If I do need to suspend a task I can just press it twice (courtesy of bind C-z send-prefix) which is not particularly inconvenient.
I’ve bound C-z r to reload my tmux config, which also isn’t something I do that often but it’s more convenient than having to type out the whole source-file command manually. A neat trick that I learnt a while ago is that tmux supports multi-action commands by wrapping them in curly braces. This is super nice both to make the config more readable, as well as allowing for confirmations that the action has happened using the display command.
set -s escape-time 0
set -g focus-events on
set -g allow-rename on
Just some more default settings, I don’t think any of these are particularly important—in fact, I’m pretty sure that first one should be set -g not set -s but evidently it’s not been an issue so it’s remained like this. I can’t remember why I turned focus events on, I think it to make some vim plugin work? I’m fairly confident that I don’t use the plugin any more, so this is probably obsolete. allow-rename allows an escape sequence to change the window name. I don’t dutifully set meaningful window names, so any program that wants to give me a useful name is more than welcome to.
# SHORTCUTS
bind c new-window -c '#{pane_current_path}' -a -t '{next}'
bind -n M-c new-window -c '#{pane_current_path}' -a -t '{next}'
bind -n M-z resize-pane -Z
On the topic of making common actions really convenient, I bind M-c to open a new window since C-z c is just a tiny bit too slow—although I keep that binding around just in case I’ve got more time on my hands, I guess. I also have set the two options here to open the new window in the same directory as the current pane (doing anything else just doesn’t make sense to me). That -a -t '{next}' means that the window will open directly next to the current one, rather than at the end.
M-z zooms the current pane—hiding all other panes in the same window—which is useful to focus on one thing quickly, or to copy text from the window.
bind x confirm-before -p "kill-pane #P? (y/n)" kill-pane
bind '$' command-prompt -I "#S" { rename-session "%%" }
bind ',' command-prompt -I "#W" { rename-window "%%" }
bind d detach
bind C-d detach
bind : command-prompt
Since I remove every single key binding, I have to add back every operation I want, and sometimes I do just want the default keybinding back. In this case I re-add C-z x to kill a pane, C-z $ and C-z , to rename sessions and windows, C-z d to detach from the session, and C-z : to open the tmux prompt.
It’s neat that these two-step commands that ask for input or confirmation are actually implemented with other tmux commands, rather than being baked into the “dangerous” commands as additional options. This means that if I really wanted, I could add a confirmation step before opening a new window, or detaching from a session.
The smart move in this section is actually bind C-d detach. I would constantly press C-z and then press d just before I’d released the control key, which result in nothing happening. Instead of learning to be more careful with my keystrokes, I just added a mapping so that mistaken keypress also did what I was intending.
bind m {
set -w monitor-bell
set -w monitor-activity
display 'window mute #{?#{monitor-bell},off,on}'
}
This is something I’ve only really added recently. You’ll see below that there’s a window style for windows with activity (ie: their shell has printed output while in the background) as well as windows that have sent a terminal bell, and I use that to change the colour of the window in the status bar. However, sometimes I find this a bit annoying, and I want to just be able to run something (like a server) in the background and not care that it’s printing output, so I have a way to turn off the monitoring for just that window.
If you don’t pass an argument to set for an option that’s a boolean, then it gets toggled. So in this case I’m relying on the fact that I don’t change these options any other way, and that toggling them both won’t ever get them out of sync. I could probably do this “properly” to ensure that they’re consistent, but it’s not really an issue I care to fix.
Another example of multi-line commands making things easier to read.
bind s send-keys -R Enter
bind S {
send-keys -R Enter
clear-history
}
Sometimes I want to run a command and then search in the output. It’s really annoying to have previous commands’ output messing up the search, especially if you’re repeatedly running a test or looking at logs and trying to search for some message. I could just open a new pane each time, but it’s easier for me to just wipe out the scrollback history in the current pane.
C-z s (lowercase “s”) is equivalent to the “clear” command, except I can do it while a command is running. C-l in most terminals does the same thing, but I have that re-bound to pane navigation.
C-z S (uppercase “S”) clears the screen and the history, again doable while a command is running.
I send Enter after clearing the screen to force any prompts to re-draw, otherwise you can be left with a completely blank screen.
# NESTED MODE
bind -n M-Z {
set status
set key-table nested
set prefix None
}
bind -T nested M-Z {
set status
set key-table root
set prefix C-z
}
If you’ve messed around with tmux enough you’ve come across the warning:
sessions should be nested with care, unset $TMUX to force
This of course is just a warning, and so naturally I have a whole system to nest tmux sessions. This is useful if you’re always in tmux and ssh from one machine to another. You don’t want to exit out of tmux locally (obviously) and you want to run tmux on the remote computer in case your connection drops so you don’t interrupt any in-progress jobs.
What I’ve done is something like a “more zoomed” mode. This will hide the status bar of the outer tmux session and disable all key bindings except one to get out of this nested mode.
So when I ssh to another machine I can press M-Z and all my local tmux UI disappears, so when I start tmux on the remote machine it looks and behaves like I’m connected directly, not nested. If I need to use the local session, I can press M-Z again and the local tmux UI reappears and the key bindings reactivate, allowing me to move around in the local session, with the remote session being relegated back to its own window.
Where this gets really clever is in my shell wrapper around ssh. It checks that I’m in a tmux session, and automatically switches to the nested mode when I start an ssh connection, so I don’t even have to press a key.
This doesn’t really work with triply-nested sessions however, since the second time you press M-Z the outer session with un-nest itself, rather than the middle session nesting itself. If I had two separate bindings—one for “nest” and a different one for “unnest” then it would work, but that would be 100% more nesting-related shortcuts to learn, and I don’t triple-nest enough to justify that.
bind -n M-V split-window -h -c '#{pane_current_path}'
bind -n M-H split-window -v -c '#{pane_current_path}'
bind V move-pane -h
bind H move-pane -v
Creating splits is one of the things I do the most, so naturally I have a no-prefix shortcut for it. I think of splits the way Vim does them, with horizontal/vertical being the way the line goes, rather than the orientation of the panes themselves. So I’ve swapped the letters for the bindings here, M-V gives me a horizontal tmux split, because I think of that as being vertical like :vsp in Vim.
These last two bindings are for moving panes into windows, but I almost never do this because it’s almost always easier to just open a fresh new split.
bind -n M-n next-window
bind -n M-N swap-window -d -t '{next}'
bind -n M-m previous-window
bind -n M-M swap-window -d -t '{previous}'
In Vim I use C-n and C-p to navigate buffers, so I wanted to use M-n and M-p in tmux to navigate windows. But I think for some reason that didn’t work, although I just tried it now and it totally does work. However my muscle memory is now locked onto the completely nonsensical M-m to go to the previous window.
The uppercase versions of both of these bindings move the window, it’s like holding down shift “grabs” the window as you navigate.
bind -n M-s choose-tree -Zs -f '#{?#{m:_popup_*,#S},0,1}' -O name
choose-tree is a neat way of swapping between tmux sessions—some people might use the next and previous session shortcuts, but I’ve settled on the navigable list.
This gets weird with my “popup” sessions (see below and the blog post I wrote about it), so I have a filter to hide them from the list, since they all start with _popup_.
bind C {
select-pane -m
display 'pane marked: #{pane_id}, move with <prefix>V or <prefix>H'
}
bind -n M-L break-pane -a -t '{next}'
C-z C is how I would merge panes back into the same window, if I ever actually wanted to do this, but I very rarely do. This works because the default target for move-pane is the marked pane, so this binding is just marking a pane to be the default for moving.
break-pane is super useful, and I like M-L as a shortcut because “l” is “navigate right” in Vim-land, and the pane pops up as a window to the right, so it all makes sense. I’ll often run a command (like a test or build) in a split and then want to continue focussing on my editor, and use break-pane to move the split into a new window without interrupting the running process.
bind Space next-layout
bind Tab rotate-window
next-layout shuffles through a predefined list of layouts for the panes in a window. It’s somewhat useful to avoid having to manually resize splits, or just as something to keep me entertained while I wait for something to finish. rotate-window shuffles the order of the panes while maintaining the same layout, which I basically use as “oh no my editor is on the right and it needs to be on the left because that’s where the editor lives” C-z Tab problem solved.
# COPY MODE
bind -n C-o copy-mode
bind -n M-p paste-buffer -p
bind -T copy-mode-vi v send-keys -X begin-selection
bind -T copy-mode-vi y send-keys -X copy-selection
I actually lied earlier, I don’t unbind every single key binding, I leave copy-mode-vi as-is. It basically just uses the standard navigation commands that I’m used to from Vim or less, so I don’t feel a need to change anything. The one thing I do set is using v to start a selection and y to copy that selection. This is what Vim does and so it’s just making things a little more consistent.
Since I don’t use mouse-mode in tmux, entering copy-mode quickly is essential. I chose C-o as it’s close to C-u which is the shortcut to scroll up, so I can quickly press C-o C-u and be scrolling up through the pane output.
bind -n M-1 select-window -t :=1
bind -n M-2 select-window -t :=2
bind -n M-3 select-window -t :=3
bind -n M-4 select-window -t :=4
bind -n M-5 select-window -t :=5
bind -n M-6 select-window -t :=6
bind -n M-7 select-window -t :=7
bind -n M-8 select-window -t :=8
bind -n M-9 select-window -t :=9
As I mentioned before, I don’t actually use these, they’re basically just here for like tradition or something. It’s basically always easier to just press M-n or M-m to cycle through my windows (I’d say I usually have <5 in a session) because that’s what my muscle memory is used to doing.
# STATUSBAR
set -g status-interval 60
set -g status-left-length 100
set -g status-right-length 100
set -g status-style bg=default
set -g status-left-style fg=colour0,bg=colour$HOST_COLOR
set -g status-left '#[bold]#{?#{N/s:_popup_#S},+, }#S #[nobold]│ #h │ %H:%M '
set -g status-right-style fg=colour250
set -g status-right '#[reverse] #(cat /proc/loadavg) '
# WINDOW INDICATORS
set -g window-status-separator ''
set -g window-status-format ' #I#{?#{window_zoomed_flag},+, }│ #W '
set -g window-status-style fg=colour245,bg=default
set -g window-status-activity-style fg=colour$HOST_COLOR,bg=default,bold
set -g window-status-bell-style fg=colour0,bg=colour$HOST_COLOR,bold
set -g window-status-current-format ' #I#{?#{window_zoomed_flag},+, }│ #W '
set -g window-status-current-style fg=colour231,bg=colour240,bold
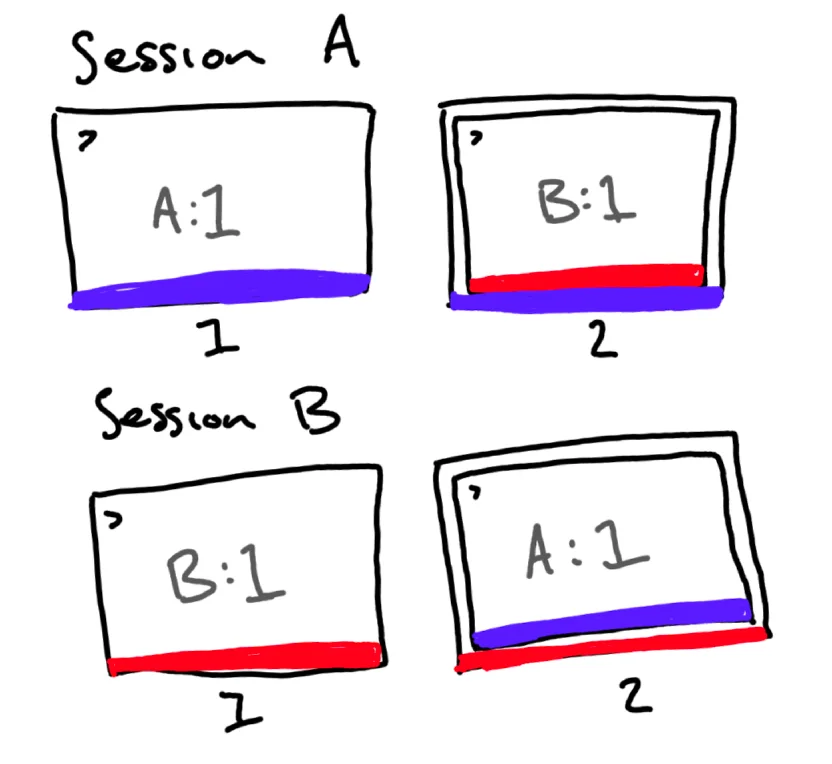
This is a super dense section, and to be honest a picture is the easiest way to communicate what it’s doing:
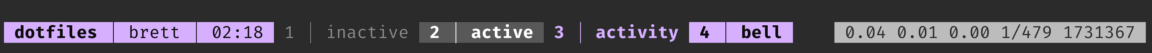
All my computers have a unique $HOST_COLOR set, and I use that to set the highlight colour for a bunch of things in tmux as well as my zsh prompt. The screenshot above shows the colour that I use on my main computer, ANSI colour 183, which almost exactly matches the highlight colour for my website in dark mode. This is something I setup when I was in university and my time was split between my laptop and a few servers fairly frequently, so having them be immediately identifiable was really useful. Now it’s just nice that I can change one file and have a new colour.
The left side of the status bar has the session name, host name, and current time. If there is a popup shell (see below) then I get a simple “+” indicator next to the session name (that’s what the #{?#{N/s:_popup_#S},+, } is doing).
The one hard requirement I have for the window indicators is that when I navigate through them, they don’t jump slightly due to the width of the active window indicator being different to the inactive window indicator. This is why I have the window-status-separator to be '' and make window-status-format and window-status-current-format take up exactly the same number of characters. I differentiate the active window with brighter, bold text and a lighter background.
I’ve been considering adding bit more info to the window indicators—perhaps removing the window number to give myself some more space—but currently the only additional piece of information is whether the window has a zoomed pane or not: #{?#{window_zoomed_flag},+, } will add a “+” after the window index if there’s a zoomed pane. To me the plus is “there’s more stuff that you might not see immediately” and I use that both for the popup shells and for zoomed panes.
If a pane has activity, then the text colour changes to $HOST_COLOR which makes it easily noticeable. If there’s a bell, then the background changes to $HOST_COLOR which is even more noticeable. Both will be cleared automatically when you navigate to that window.
I have my build scripts send a bell when they finish so that I can kick them off in another window and then easily see when they finish. I’ve also recently added a neat feature where instead of just sending a bell, they set the tmux bell style to have a green or red background depending on whether the build (or test) passed or failed, and then send the bell. This way I can emotionally prepare myself before switching windows to look at the failure.
The right side of the status bar is basically just free space, I have it set to just dump the loadavg there, which I find vaguely interesting to watch as I do a particularly resource-intensive task.
# MESSAGES
set -g message-style fg=colour232,bg=colour$HOST_COLOR,bold
# PANE SPLITS
set -g pane-border-style fg=colour238
set -g pane-active-border-style fg=colour252
# CLOCK AND COPY INDICATOR
set -g clock-mode-colour colour$HOST_COLOR
set -g mode-style fg=colour$HOST_COLOR,bg=colour235,bold
This basically just makes the rest of the tmux UI match my existing styles, using various shades of grey to indicate what’s active vs inactive and the $HOST_COLOR where a non-greyscale colour is needed.
# ACTIVITY
set -g bell-action none
set -g monitor-activity on
set -g monitor-bell on
set -g visual-activity off
set -g visual-bell on
set -g visual-silence off
These basically just set the various options needed to get tmux to listen out for a bell coming from a pane. I think I understood these options when I set them, but if I wanted to change them I’d have to re-read the tmux manual to make sure I got what I wanted.
# POPUP SHELL
bind -n M-J display-popup -T ' +#S ' -h 60% -E show-tmux-popup.sh
set -g popup-border-style fg=colour245
set -g popup-border-lines rounded
# support detaching from nested session with the same shortcut
bind -T popup M-J detach
bind -T popup C-o copy-mode
bind -T popup M-c new-window -c '#{pane_current_path}'
bind -T popup M-n next-window
bind -T popup M-m previous-window
bind -T popup M-L run 'tmux move-window -a -t $TMUX_PARENT_SESSION:{next}'
This is a slight extension of the popup shell I wrote about last year. I changed the shortcut from M-A to M-J as I found that a bit easier to press. I also added a binding to get into copy-mode so I could scroll up in the output.
Against my better judgement I also added bindings for creating and navigating windows. I don’t really use this, but I find the idea of secret hidden windows somewhat amusing.
The same shortcut I use for break-pane will move the window from the popup into the session it is popping up from. Realising that you can move tmux windows between sessions is fun. There are no rules! Isn’t that awesome!
# PUG AND LOCAL
source ~/.pug/source/tmux/pug
if '[ -e ~/.tmux-local.conf ]' {
source-file ~/.tmux-local.conf
}
I still use my package manager pug, that I wrote in 2017 to manage my shell packages. I’ve since accepted that no one else is going to use it and have just merged it into my dotfiles repo. The only tmux package that this loads is vim-tmux-navigator which I forked from the original in order to make it installable from pug.
It seems a shame to relegate vim-tmux-navigator to the bottom since it’s one of the neatest tricks to make tmux more usable for Vim enthusiasts. But this is what the format demands. For the uninitiated, it adds shortcuts to Vim and tmux to navigate splits with C-h/j/k/l—so you can navigate the splits interchangeably. I forget that I have it installed, splits are just splits and I don’t have to think about how to navigate them.
All my config files will check for some -local variant and source that if it’s present, which allows me to make per-machine customisations that I don’t want to commit into my dotfiles repo. This is great for work-machine-specific options.
Bonus Round: mx Helper Script
My other interaction with tmux is with a script called mx that originally papered over the list-sessions, attach, and new commands but has since gained responsibility for switch and rename-session.
The gist is that I want to be able to type mx my-session from anywhere and then be in a session called “my-session”. The “from anywhere” requires a little bit of thought:
If we’re outside of tmux, use new-session -A to attach to a session if it exists, or create a new one with that name.
If there’s only one window in our current session, we probably don’t care about the current session staying around. So if the session we’re trying to switch to exists, move the current window to that session, then switch over to it.
If we’ve only got one window and the target session doesn’t exist, we can just rename the existing session to the target session name.
If there’s more than one window in the current session, then create or switch to the new or existing target session and move the current window along with us.
This is almost certainly unnecessary, but it avoids me leaving a trail of sessions that I’ve finished with and avoids me having to exit out of tmux to switch between sessions, which is what I’d have to do previously to avoid the nested-sessions error, since the script would try to attach while already inside of tmux.